Several other observations:
- when the input is run in a cluster, several child runs remain stuck and eventually complete (i.e. in a run with 5 CPU cores that should take 30 minutes, 4 of them complete in 30 minutes and the last in >2 hours). You can verify this by running 10000 primaries with spawn=5. I have noticed that the core that gets stuck in general has more of these ELSCKN and Emsnsc calls.
-
- Two simulations are done. RunA with Np_tot=5e6 histories, 1e6 primaries over 5 CPU cores and the other RunB with Np=166667 particles over 60 CPU cores (i.e. ~Np_tot=1e7). Attached three plots:
→ the uncertainty in the results of one of the child process of RunA (i.e. 1e6 primaries simulated)
–> the uncertainty of the total primaries of runA (i.e.5e6 primaries)
→ the uncertainty in the results of RunB (i.e. 1e7 primaries)
- Two simulations are done. RunA with Np_tot=5e6 histories, 1e6 primaries over 5 CPU cores and the other RunB with Np=166667 particles over 60 CPU cores (i.e. ~Np_tot=1e7). Attached three plots:
What is the reason for such similar uncertainties in the area circled red (it is a layered wall with progressive importance)? shouldn’t the uncertainty of RunB be much less?
The biasing is different for both runs but the gradient between layers in the wall is comparable,
runA_1e6:
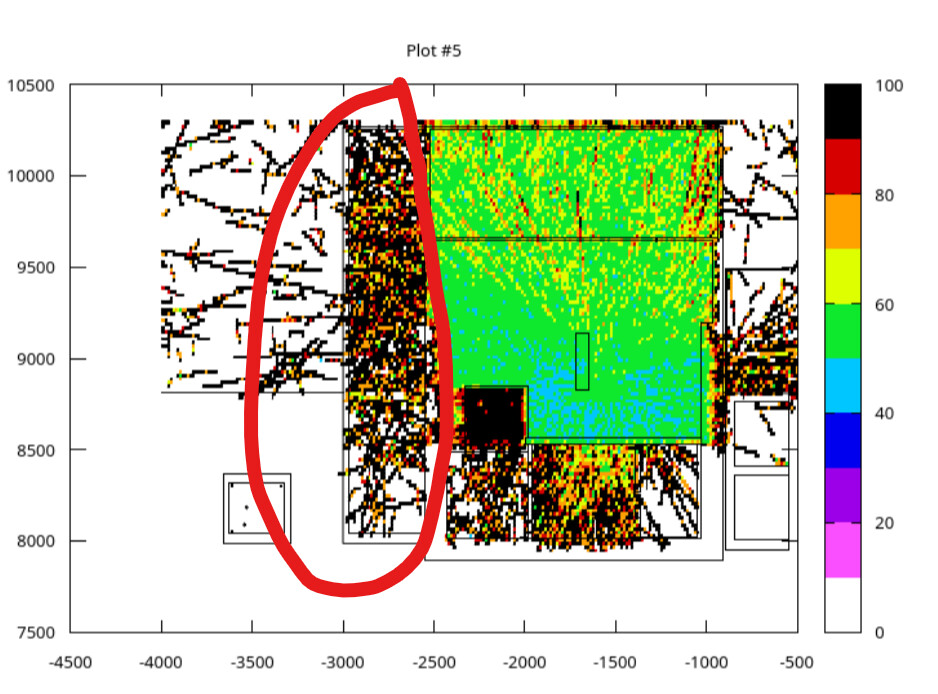
runA_5e6:
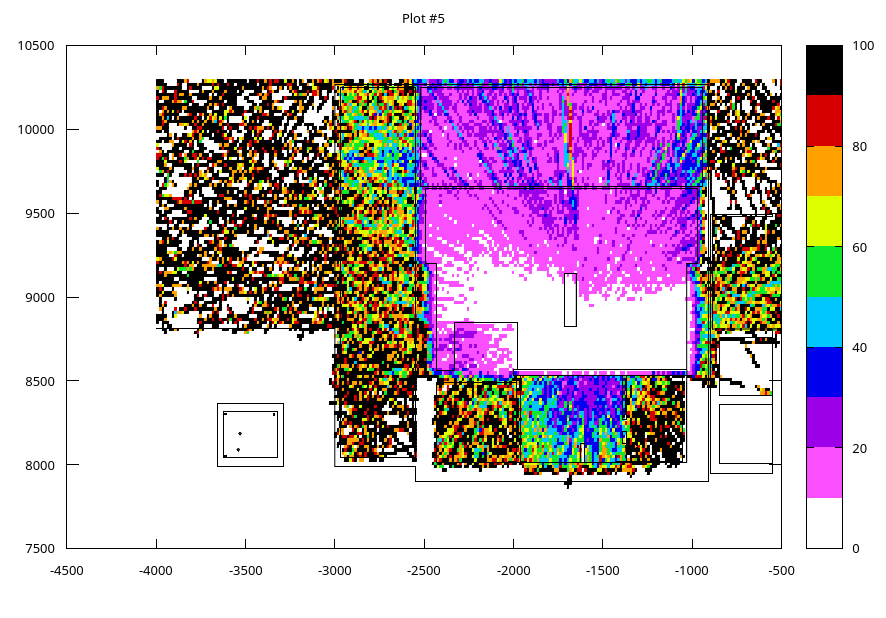
runB_1e7:

montypy4_runA.inp (1.2 MB)
montypy4_runB.inp (1.2 MB)
I attach my inputs for both runs if needed and looking forward to your prompt reply!
Best wishes,
Marco
I note also that the error in the results got worst when the blackbody was introduced around the region Surr. Below is what it was before the introduction of the blackbody (with 5e6 primaries):

The problem with this scenario was that a second source of radiation in the wall was manifesting. The blackbody region around “Surr” was introduced to keep the radiation only in what we want to irradiate (i.e. the target)
