Dear FLUKA experts,
I’m running FLUKA on our cluster and I wanted to utilized the “spawn” option present in FLAIR. That is, run many cycles with one cycle/CPU.
So I wrote the Following slurm script “Example_FLUKA_Sbatch.sh” to do this. I ran the code with one of the examples that came with the code “example.inp”
BUT this only prints output files for one cycle even after creating the temporal directories just after the simulation is lunched. (see screenshots and zip folder)
Please kindly advice. fluka_cluster.zip (1.4 MB)
I found the following codes in the manual and the post you refenced.
usrsuw.f: to read out the RESNUCLEi output
usysuw.f: to read out the USRYIELD output
usxsuw.f: Baoundary Crossing Fluence
usbsuw.f: binning Estimator
ustsuw.f: to analyze USRTRACK binary output
…
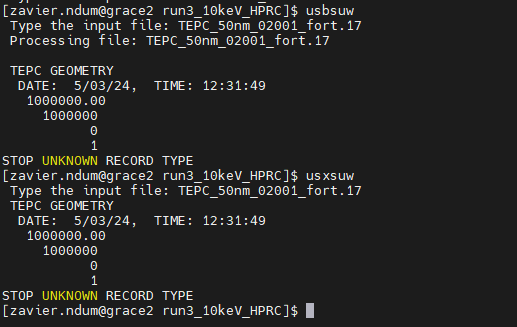
But what about the DETECT card? (__fort.17)?
I’m simulating energy deposition events recorded by this DETECT card and so far, I’m unable find a way to process the results in the command line (see photo)