I am running a testing setup to see how FLUKA handles imported energy spectra sampling, following instructions on this page: Sampling from energy spectra. However, I found it a bit confusing for me to understand how this sampling works unit wise. According to what this says, Sampling from energy spectra, it doesn’t matter what unit I choose for the external spectra. However, I found it is not the case when I run my setup.
In my setup, I am shooting proton beam through vacuum while setting an USRBDX estimator right in front of the source. Now, if everything works as the guideline indicates, no matter what unit I choose for my source, the spectra generated by USRBDX should look the same and also same as the input external spectra if I convert everything into the same unit. Therefore, I tried 2 different input spectra to test this. First, I used probability as my 3rd column arguments for the external spectra file, which is unit-less of course (or part/pr). Then, I converted the probability into fluence, dividing it by the area of the detector and then the bin width. Now, the 3rd column should have (part/pr/cm^2/GeV) as unit. Yet, the spectra generated by USRBDX is not the same for these two runs. What did I do wrong?
The attached is my input file and the external energy spectra (The 3rd column is probability not fluence for this file) for the setup if you want to take a look.spectra_sampling.inp (1.2 KB) TSP.txt (1.8 KB)
I’m not sure I fully understand your approach converting from probability to fluence.
What is meant by “independent of the unit” in the instructions is the following: the third column is a value which is used as a measure of probability that a particle within the energy range associated with this bin will be emitted. The absolute value of the third column is not of importance. For example you could have a spectrum that looks like
1.0 1.1 2
1.1 1.2 4
In this case the probability of your particle to have an energy between 1 and 1.1 is half of the one than having an energy between 1.1 and 1.2 GeV. You could achieve the same thing with
1.0 1.1 4
1.1 1.2 8
in the end it is only the ratio of the integral of the first and the second bin which is important for the sampling.
I fully understand your explanation on the “independent of the unit” part, and I have tested it with my setup. However, the thing I do not understand is that how does FLUKA interpret this source. In the README file that come with the routine package, all 3rd columns have fluence as their arguments with 1/(cm2 * GeV) as unit. Which to me this means that FLUKA need the spectra’s information divided by the bin width. This won’t be a problem if the spectra is binned linearly, as it will only introduce a factor and will then be simplified. But, does FLUKA knows how to handle it if the information on the spectra is binned logrithmically?
Sorry if my description of the problem couldn’t be more clear, this is part of the reason why this issue bugs me.
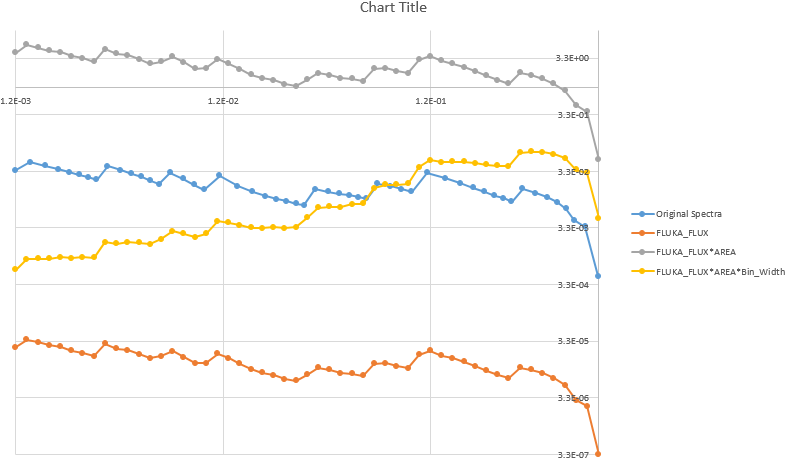
So to illustrate my point clearer, the attached is my plot. As you can see, I could not get the FLUKA estimation on top of the original data. In theory, they should only off by a bit and the numbers needs to add up to one.
I think there is a slight misunderstanding of terms here, so please allow me to indulge into some technicalities. What the code does is to emit particles with an energy following a defined probability distribution function (sometimes also called probability density function). Note that this is not the same as probability! To illustrate this consider a random variable/event X for which the probability of occurrence is P(X). Then the probability density p(X) is the derivative of the probability dP(X) / dX.
Here you might start to see the similarity with a (differential!) fluence spectrum where you know the fluence per energy bin --> dF(E) / dE
The actual probability of seeing such an event within the specified bin is then the integral p(X) * dX == dP(X)/dX * dX. If we look at it from the point of view of a differential fluence spectrum, which in principle is a probability distribution function, then the probability of finding a particle within a specific energy bin dE is equal to dF(E)/dE * dE.
So the code actually finds the probability by integrating the probability distribution function (3rd column) over the associated bin width. Then random numbers are used to represent this probability and the README file in the archive sketches out roughly how it works. There are three different methods provided and you can find a more detailed description how they work here. The actual implemention is a bit more tricky as it also allows for propagation of uncertainties in your input spectrum.