Dear all
Please I would like to know what is the difference between the 2 RUN MODE or exactly is the same without any differences
Best Regards
Fayez
Hello Fayez,
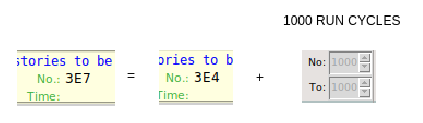
in one case you are running 3E7 primaries in one cycle, while in the other you are running 3E4 primaries in one cycle looping over 1000 cycles.
The total number of particles simulated will be the same. However, during the calculation of the statistical uncertainty for the scored observable, FLUKA takes in account how many cycles have been run. (see also this question in the forum: Statistical error).
Also, consider pages 27-30 from the FLUKA course lecture: https://indico.cern.ch/event/1123370/contributions/4715934/attachments/2444331/4188477/02_Monte_Carlo_Basics_2022_ULB.pdf
Overall, in your specific case, the former run mode would not be suitable for the estimation of the error.
Cheers,
Daniele
Many thanks Daniele Calzolari
My problem with this, I have after running 1000 cycles I have got a huge files represented in, 1000 file of *.log (zero bit), 1000 file of *.err, 1000 files of *.out, and ran (filename) (1.6k) and all is not needed for me. I see this as a waste of time the hardware, of the computer memory, and of data storage (hard disk) without any need.
I suggest that ; FLUKA has to have a control method to control the needed output files for users.
Best regards
Fayez
Hello Fayez,
I certainly agree with you that 1000 cycles might be excessive for most applications.
Indeed, on page 29 of the second link I sent you, the suggested number of cycles is between 5 and 10.
For this specific case, I would split the simulation in 3E6 particle per cycle for a total of 10 cycles, which should be an acceptable tradeoff.
Thank you for your suggestion.
Cheers,
Daniele
Dear Daniele
Really many many Thanks for your quick response and for the prompt reply. This advises will help me a lot.
One hint: for the auxiliary files like ( *.log & …) that Fluka can need during the run mode (which not needed to the user). It can be directed to a temporary directory.
Best regards.
Fayez