Searching for an advice for how to speed up the running of simulations in order to use all the capabilities of the computer you are working on…
On other words using UBUNTU 18.4 or higher how to install or adjust FLAIR to use perfectly all the maximum speed and memory available on My PC?
Ps UBUNTU not working under Windows. It is the only operating system used.
FLUKA usually takes all the memory it needs and uses the full computing power of a CPU. The only optimization you can do is increasing the number of jobs that are running in parallel on different cores (or CPUs). First you want to look up how many CPUs you PC has. You can do that by typing
lscpu
in your console. You get a bunch of info with one line reading
CPU(s): X
X is the number of cores available.
To use more than one at a time from FLAIR, you have to install the task-spooler (tsp) package
sudo apt-get install task-spooler
and activate it with
tsp -S Y
with Y the number of cores you want to run on, e.g. Y=5. (I suggest to choose Y less than your number of available CPUs X if you want to use your PC while waiting for FLUKA to finish). You might want to write this line into your ~/.bashrc file so you don’t have to activate it again after restarting your PC.
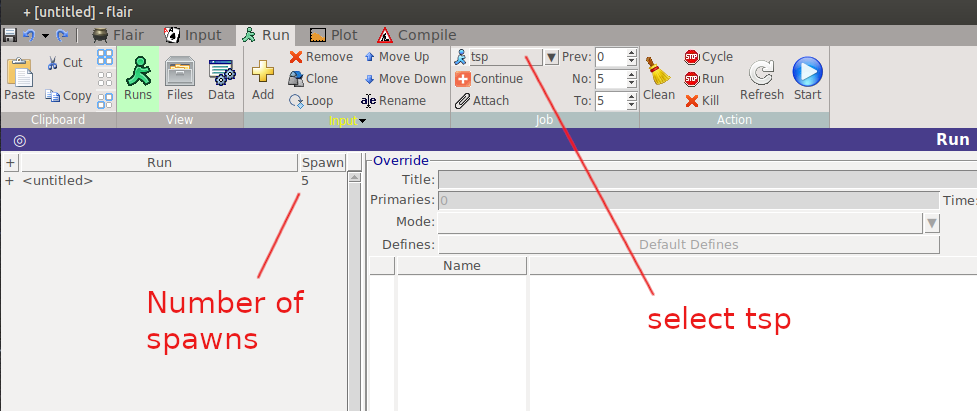
Next, in the Run tab of FLAIR, create as many spawns of your job as you made available to tsp (Y=5 in my example) and select tsp in the dropdown menu.
Starting the simulation should now run Y jobs in parallel, meaning you can decrease the number of cycles or primaries by a factor of Y and still get the same statistics
Dear @mohammed.fayiz,
optimization of your FLUKA code and the way how you run job will give you significantly higher performance boost that optimization of the FLUKA installation.
Modern virtualization technology allows to run FLUKA task from Ubuntu installed using Windows WLS virtually with the same performance as from pure Ubuntu installation. The main difference is that you PC will not run background Windows tasks at the same time, if you have direct Ubuntu installation. THe FLUKA installation routine described in the manual is quite optimal, so keeping all pre-required libraries updated is the main recommendation.
.
You have to know your required model accuracy and hardware configuration to optimize calculation performance and adjust your code accordantly.
Main suggestions to improve performance of calculations are following.
Estimate required precision of the simulation according to your needs: optimal statistics that fulfil accuracy requirements, select scored regions area and resolution according to your real needs, select particle transport thresholds according to your physical model. It is efficient to “trap” particles in the black hole region, if it is not important to score them. Remember that MC estimator accuracy depends non-linearly on the number of primaries: sigma = 1/sqrt(primaries number).
Minimize usage of parenthesis in your geometry definition.
Use multithreaded job ran. Optimal is to set number of spawns (Runs card in Flair) as N-1, where N is the number of physical cores of your CPU. Here is one trick, that if cooling of your CPU is not sufficient, PC will decrees CPU frequency, so advantage will not be linear to the thread number.
Select scoring volume according to the memory available in your PC (e.g. number of USRBIN scoring card and total number of bins, 1000 x 1000 x 1000 mash requires 8 Gb of memory to allocate). You will minimize your hard drive / ssd recall events, and increase performance. Fluka biasing technique https://indico.cern.ch/event/956531/contributions/4020245/attachments/2121550/3570935/14_Biasing_2020_online.pdf may help you to optimize scoring complexity.
If you have computation time limitation for a certain model/project, feel free to consult on its optimization! Note, that regardless listed recommendations, many tasks cannot be calculated using a conventional PC with the reasonable accuracy, so usage of the computer cluster is required.
Dear Illia Zymak many thanks for this fast valuable advice. I took a lot of your time, so sincere thanks
kindly I would like to ask
1- for example for USRBDX i- what is the faster operation is it using one energy range from Emin to Emax directly or to divide it into parts
ii- from region to region is the width of the net region can affect the speed and I have to divide it to small width regions too
2- for incident beam a collimated incident beam with small dimension target is better to simulate and faster than others ?
3- What is a computer cluster minimum specifications that can helps and make the work correctly. ِAnd is there is a world group for this one can join?
And it is mentioned that the Ubuntu 20.04.5 LTS is more lighter. Do you think it is help.?
4- it is recommended to press the refresh during calculation What is the similar method for such a process can automatically done while the program is running
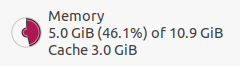
5- During the running I found that the program used 50% of the ram and work slowly How it forced to use all the memory value
Dear Mohamed Fayez-Hassan,
Than you addressing your questions.
1 - For USRBDX estimator direct splitting of regions or ranges will not provide you faster operation, but rather slow you down with the further processing. What is important is the number of bins, you dividing your energy interval. So, if you have some less important energy range, or you want extremely high energy resolution within a small region of the range, it will be reasonable to split this specific regions to a separate estimator with different settings.
2 - It is important for you, what time do you need to accumulate required statistics over required region.
So for you it is important do force your model to trace particles that are not important for you. In general, if you have small region or region divided to many small energy or coordinate bins you will need more primaries (so calculation time) to accumulate proper statistics.
3 - That is quite particular question. It depends to what cluster your facility may provide you an access. Typically, it make sense to use the cluster if it will provide performance gain at least one order of magnitude. First you should consider, consider if you may dimension your tasks to capabilities of your PC by previously discussed methods. Use of various OS typically effects performance for marginal 10-20%, so I would not take care about it.
4 - Actually “refresh” does not effect performance of FLUKA. When you press “refresh” you just force FLAIR to request FLUKA status before the scheduled interval.
5 - As @rmartin said, FLUKA can use all allocated memory, so more memory is not needed for your task. You can get some performance issues if your project allocates nearly all available memory.