Dear @Mihaela_Parvu,
In view of this discussion, I got some doubts regarding the source_newgen.f that has been shared here.
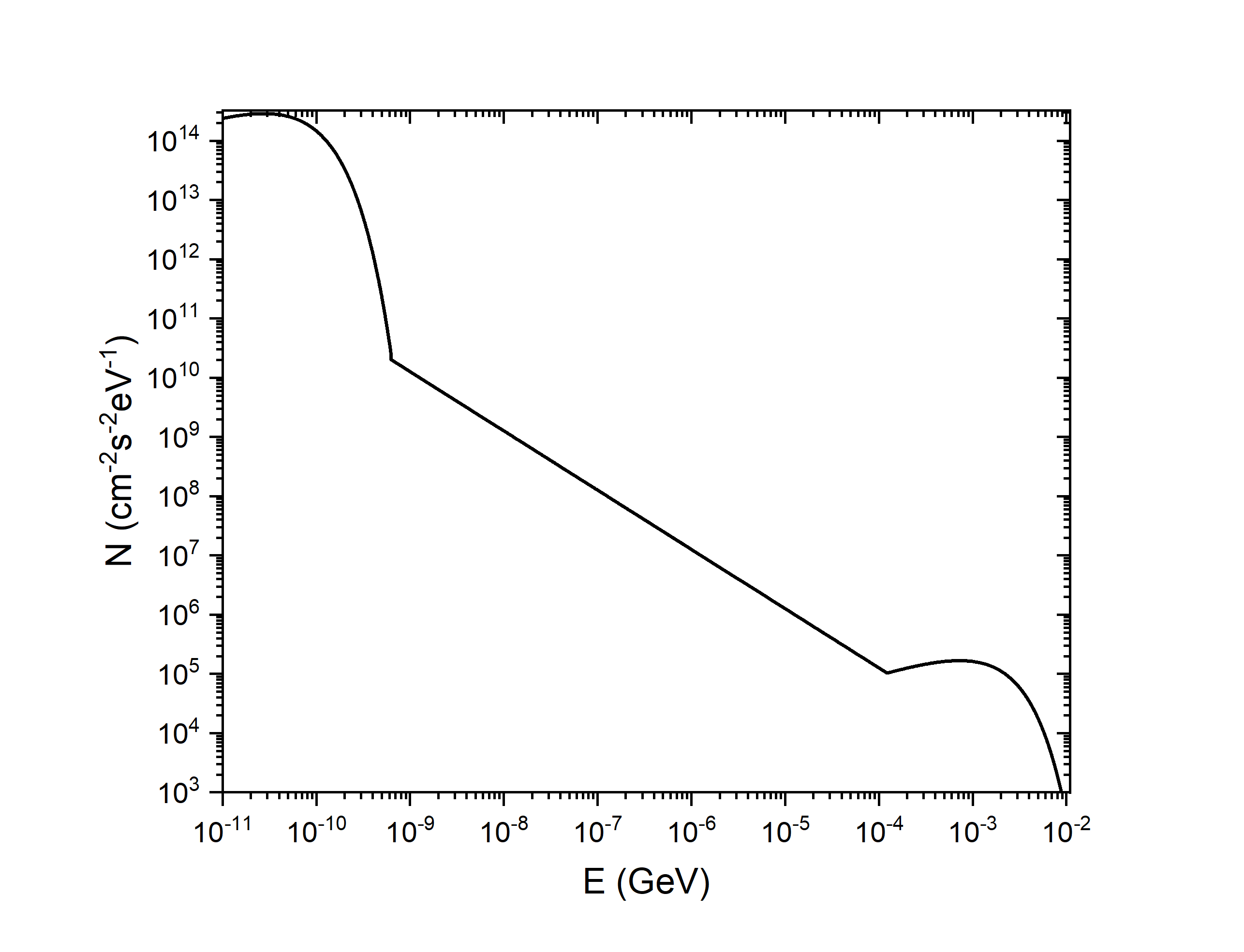
I am sharing here one journal that I found on this topic which may be helpful in this context. Please see equation (2) in the attached journal. I am sorry that I was unable to fully understand the solution given in the thread.
In the source routine shared in the thread, rand_en = FLRNDM (xdummy) gives random number between 0 to 1.
Now, in the following lines, I am not sure if “0.625 e-9” - this lower value will be there in the output random number. Also, we will lose statistics (more computational time will be invested) since we are considering only upto 10E-3 value of the random number, rest of the numbers i.e. above 10E-3 to 1 are not considered here, so we will unnecessarily waste some of the computational time.
if (rand_en < 0.625 e-9) then
momentum_energy = sample_maxwell_boltzmann_energy( temperature )
momentum_energy = sample_maxwell_boltzmann_energy( [temperature] )
else if ((0.625 e-9 < rand_en) .and. (rand_en < 122 e-6)) then
momentum_energy = 1/momentum_energy
The formulas mentioned in equation (2) as well as in this thread are for flux distribution with some coefficients in the equation. If we directly apply the term ‘sample_maxwell_boltzmann_energy( temperature )’, will the coefficients be taken into account ?
Is the term “momentum_energy” in the source_newgen.f same as TKEFLK (NPFLKA) in the source.f ?
On this topic, is there any documentation available if we want to use Maxwell Boltzmann sampling distribution in source.f, instead of using source_newgen.f, since we can easily modify terms in source.f ?
(I mean is there any call option for the same? )
Also, how is the code employing this distribution? Is it converting the MB distribution formula (PDF) into a histogram internally and then is it using the histogram for sampling ? or is it using MB distribution PDF and converting it into a continuous CDF and then is it using that CDF for sampling (like it does in case of isotropic sampling) ?
You were correct!
I don’t know what is the easiest solution, but I tried to split the parametrization into several energy ranges, for example:
for E < 0.625 eV
limit1 = FLRNDM (xdummy)
if (limit1 < 0.625) then
momentum_energy = limit1 * 1e-9
particle_weight = sqrt(momentum_energy) * 2.8554 * 1e15 * exp(-18.22*momentum_energy)
WRITE(71,*) momentum_energy, particle_weight
end if
for 0.625 eV < E < 1 eV
limit2 = FLRNDM (xdummy)
if ((0.625 .le. limit2) .and. (limit2 < 1 )) then
momentum_energy = limit2 * 1e-9
particle_weight = 1.2642*1e10 * (1/momentum_energy)
WRITE(71,*) momentum_energy, particle_weight
end if
I still did not manage to get the spectrum from the paper, so I am pretty sure that I am doing something wrong. If you have time, please take a look at the source file, maybe you can point out the mistake.
Thank you for the discussion which might be useful for some of my future source definitions.
Thank you @Mihaela_Parvu for working on this topic. I found some issues in the code. Let me explain:
My biggest concern is whether we can directly insert the flux equations in the particle weight. Is there any other threads supporting this approach? For example, let us consider the two step methods that have been discussed in the forum several times, where an USRBDX (lets say) output needs to be incorporated in the second step. I have never inserted them in particle weight, rather I have estimated probabilities from that energy distribution output and then I have carried out sampling using that discrete probabilities. I am not sure if we can directly put the 3rd column of the tab.lis output of a USRBDX scoring as particle weight at that corresponding energy in 2nd step method. If this is a right approach, then it will be a blessing (at least for me ) in a way that it will be an easy approach to handle a 2nd step method. FLUKA experts may please comment on that.
The sampling seems to be fine (except from the fact that I am not sure if it is right to put them in particle weight, as I mentioned above). However, another mistake arises because the coefficients are actually having energy units, and the flux values are given in eV ^-1 unit (for example if you look at 3rd equation, the exp and root term is having a value 1E-6 which is appearing because E is in eV. In FLUKA we use GeV unit, so accordingly we have to modify the coefficient values. This is true for other two energy ranges , so carefully we have to understand first how these coefficients are coming.
Please adress this:
This is essential because let’s say, in a particular history, limit 1 and limit 4 if conditions are getting satisfied ( since limit 1 to 6 were independent of each other). Then we get two sets of momentum_energy with corresponding different weights . So at one history, there will be multiple sets of momentum_energy and particle weight. (This can be checked : use 10 as no of histories, put 1 in cycle, then check the size of the output write files ( unit 71), the size is more than 10 entry sets. Will this create any issue in simulation? or is it perfectly fine to have multiple neutron energy each with different weights for a single history ?
I looked into source_library.inc file and there I found that
TKEFLK (NPFLKA) = momentum_energy
WTFLK (NPFLKA) = particle_weight
Using the source file attached to this message in the _fort.71,72,73,74,75,76 files I obtain this spectrum by plotting the particle_weight function of the energy (looks like the one from the paper that you sent).
There is a problem indeed with doing so with the old file because of the explanation that you gave.
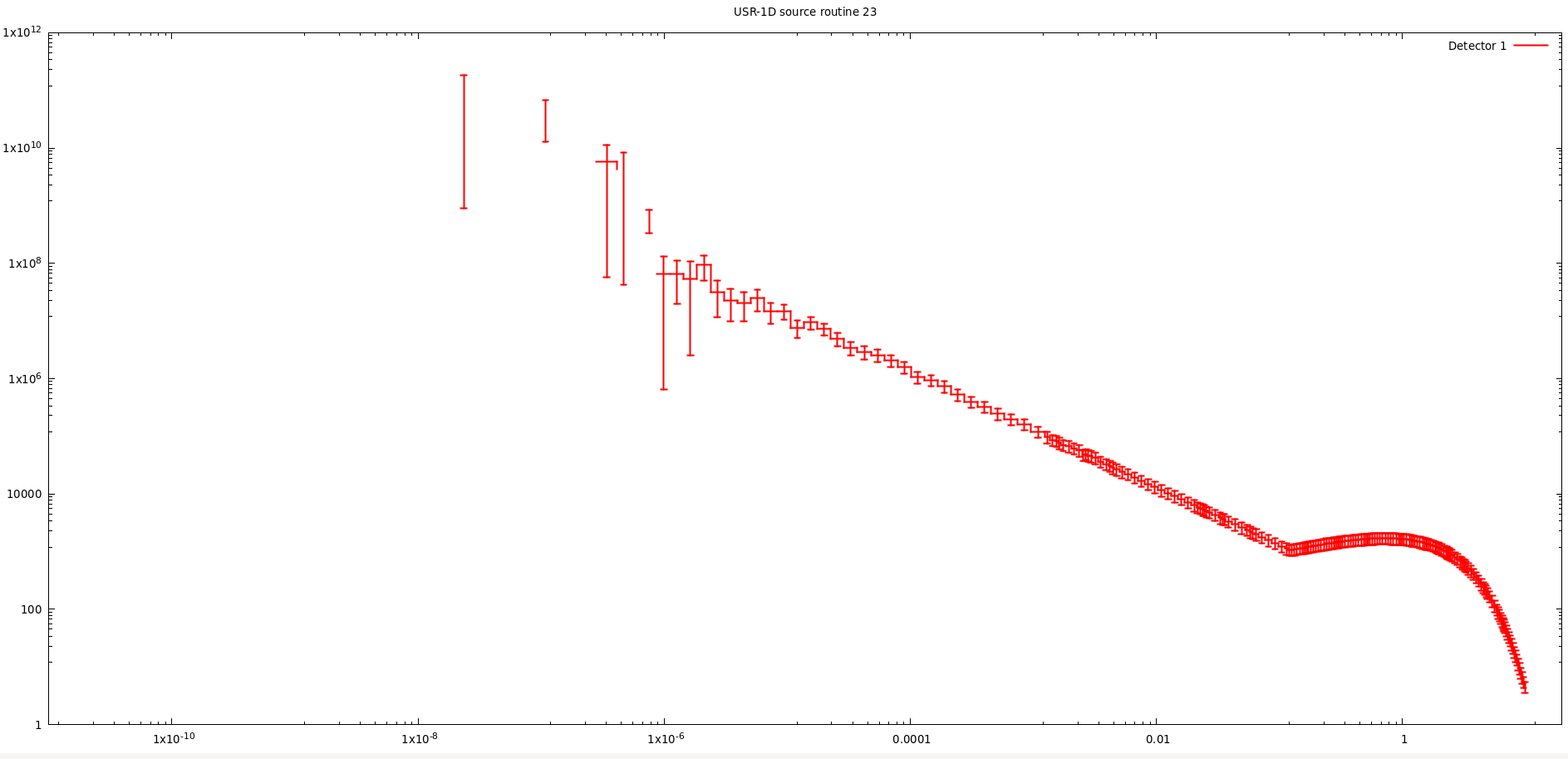
I think it can be done with the attached source, but I still don’t understand why the statistics is so bad at low energies even if I ran 4e7 particles and the variable of the energy (j) is uniformly distributed - maybe because of the random number generator which doesn’t return very small values (I am still looking into it).
Thank you @Mihaela_Parvu for the discussion. Yes, I did the same to generate the spectrum, by storing the values in ev units and then putting them in the flux equation. But as we discussed, I am not sure if putting them as weights will solve the purpose. However, we can always make histogram form it and use it (initially I was hoping if there is any other way out, using the flux function directly). I am planning to learn the irradiation, decay etc features in FLUKA, and once I become comfortable with the basics, I will get back to this problem.
I am facing a similar issue of low statistics at lower energies. I got the spectrum after discretizing the equation into 55 groups but with very poor statistics in thermal neutron regions.
I had a look at thread and I would like to offer a couple comments.
The momentum_energy in the new source routine means TKEFLK (NPFLKA) or PMOFLK (NPFLKA) whether the energy_logical_flag is true or false.
Using the flux equation as particle weight, while sampling the energy uniformly is a valid way to create a biased source. Please note, some features (like the DETECT scoring requires an analogue simulation and using this source would give meaningless results.) This works well where the energy range only in a “linear range”.
The issue with this biased source when a neutron spectrum needs to be recreated, that the energy range spans from 1e-5 to 1e7+ eV. This means a uniform (linear) sampling would barely give number from the lover end. (This is what you saw)
The neutron spectrum has the special feature, that is mostly flat (with two peaks) in a lethargy plot, meaning that the bins of the histograms contain comparable number of neutrons, even though the difference of energy with of the bins if huge. So, a simple solution would be to convert the flux equation into a histogram.
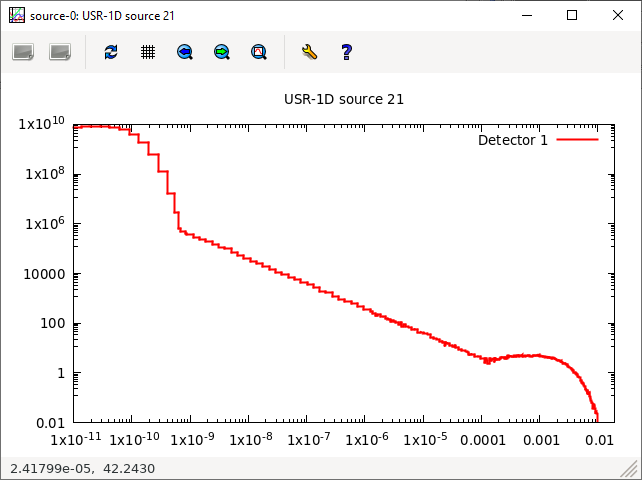
Furthermore it is possible to convert the flux equation into energy, intensity value pairs, and assume a linear transition between the points. This also can be used for sampling. See the attached spectrum file and source routine.
Thank you @horvathd for the insight. It was very helpful.
Just to clarify things,
the neutron_spectrum.txt attached here is obtained from separate computation (could by done by fortran or python or matlab etc), by converting the flux equation into a histogram, right? The source_newgen is just reading that .txt file. Is it so ?
The particle weights are fixed to 1 in this source_newgen.f, right ? From the second column of the txt file, it is calculating probability and accordingly energy of the neutrons will be chosen in each history. Is it right ?
It will be a help if you kindly address this. Also, as you mentioned , does the comment ’ feature of sampling from a spectrum will be included ) refer sampling from histogram ? (Like we need the histogram txt file to utilise this, is it? ) Or is it different ? Like sampling from a continuous spectra instead of histogram ?
As a note, is there equivalent source.f routine for this source_newgen.f ? It will be helpful in case a complex geometry sampling is needed which cannot be achieved in the newgen format .
Yes, you need to create the spectrum file separately. I used excel, but it can be done with any program. The source routine will only read this file.
The particle weight is kept as 1, so it is suitable in cases where analogue simulation is needed.
There is a difference between a “histogram sampling” and “spectrum sampling”.
In a histogram you need to provide the lower and higher energy boundary of a bin along with the intensity of the bin.
For a spectrum sampling, you only provide energy points (n), and the intensity at these point. Then the sampling code will create (n-1) “bins” from these points, with the assumption of a linear transition between the points.
The old source routine won’t be updated. The spectrum (and histogram) sampling code will be (is) in the source_library.inc. You may try to include it into the old routine by yourself. I don’t understand what limitations do you encounter using the new routine in large geometries, what you can only do with the old one.